Oh ... thnx will do!
joeldebruijn
joined 2 years ago
It looks like this (by default after install):

I read in the documentation Youlag is included in FreshRSS so I didnt tinker with it ....
Just for this returned to FreshRSS on tried it on my Yunohost server. Added a youtube user feed and got a list of their latest videos. They dont actually seem to be playable tho? No play button, just a picture and the link.
Dont know if they are supposed to have controls?
Although feeling the same as the other commenters, I gave it benefit of doubt. Using it for 2 groups, Openstreetmap and CoMaps. It works more or less.
Also ... dynamic changing them after my wallpaper rotation every 10 minutes, based on the colorpalette of the background photo.

You asked why and I gave an explanation where the 27 downvotes came from. So I think there is some agreement within this lemmy about being offtopic.
If that bothers you too much I suggest focusing on something more productive, as I will do.
Not selfhosting AND privacy.
From the sidebar of this lemmy:
"A place to share alternatives to popular online services that can be self-hosted without giving up privacy or locking you into a service you don’t control."
So its about self-hosting with certain qualities (not giving up privacy or lockin). Not about privacy in general.
Signal isnt selfhosted and does lock you in, albeit with a high reputation to not become evil.
Better lemmy would be https://lemmy.ml/c/privacy
Nothing to do with selfhosting
I just see those foundation onboard / leaves from afar ... but isnt the retention rate way to high to do actual foundational stuff?
I am dutch and spend many an hour at the intersection of IT and Privacy ... but this is the wrong community to advertise a local Signal group.
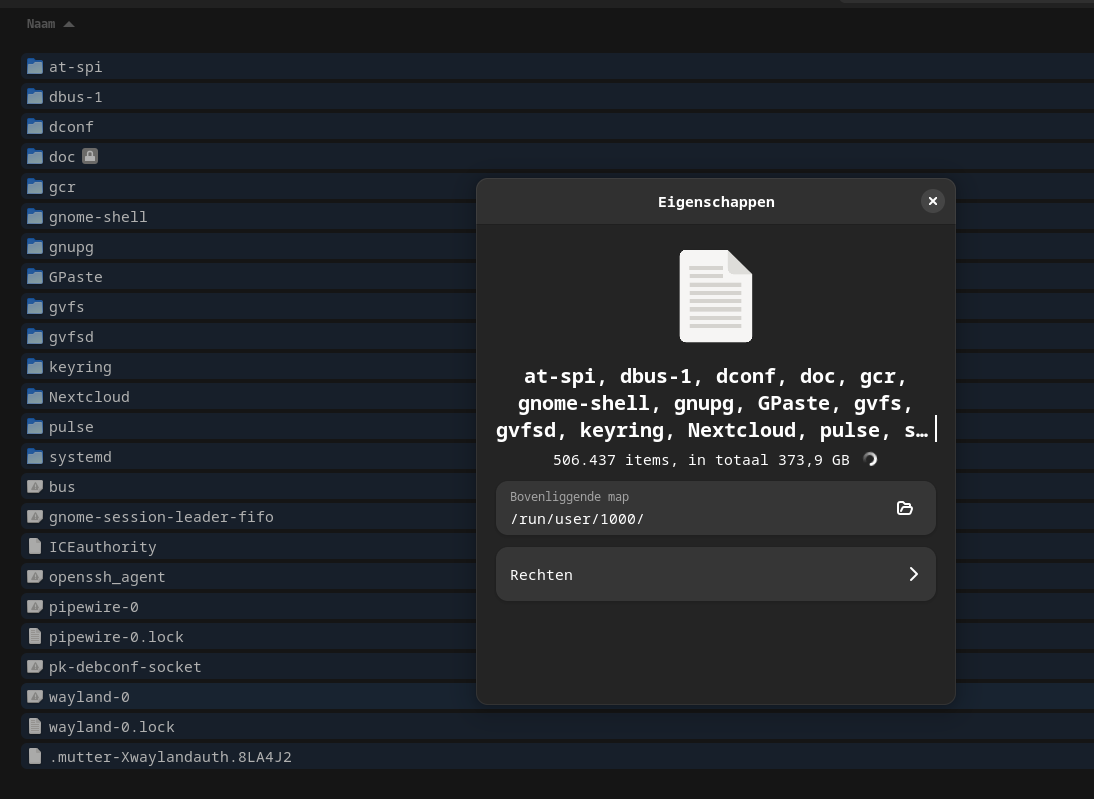
My main question is about /run/user/1000:
- Should I avoid touching it?
- Could I delete it?
- Is there something wrong with it?
Background: I'm fairly new to Linux and just getting used to it.
I use fsearch to quickly find files (because my filenaming convention helps me to get nearly everything in mere seconds). Yesterday I decided to let it index from root and lower instead of just my home folder.
Then I got a lot of duplicate files. For example in subfolders relating to my mp3 player I even discovered my whole NextCloud 'drive' is there again: /run/user/1000/doc/by-app/org.strawberrymusicplayer.strawberry/51b78f5c/N
Searching: Looking for answers I read these, but couldnt make sense of it.
- https://unix.stackexchange.com/questions/162900/what-is-this-folder-run-user-1000
- https://forums.linuxmint.com/viewtopic.php?t=412850 So if its a bug with flatpaks I'm inclined to delete a certain db at ~/.local/share/flatpak/db
Puzzled:
- Is this folder some RAM drive so my disk doesnt show anything strange? Because this folder doesnt even show up at the root level.
- Are these even real? Because the size of it (aprox 370 GB) is even bigger then my disksize (screenshot).
Any tips about course of (in)action appreciated.
view more: next ›
For more discussion on the value of the term "No code" I can recommend this: https://vger.to/lemmy.ml/post/35466470