Selfhosted
40266 readers
409 users here now
A place to share alternatives to popular online services that can be self-hosted without giving up privacy or locking you into a service you don't control.
Rules:
-
Be civil: we're here to support and learn from one another. Insults won't be tolerated. Flame wars are frowned upon.
-
No spam posting.
-
Posts have to be centered around self-hosting. There are other communities for discussing hardware or home computing. If it's not obvious why your post topic revolves around selfhosting, please include details to make it clear.
-
Don't duplicate the full text of your blog or github here. Just post the link for folks to click.
-
Submission headline should match the article title (don’t cherry-pick information from the title to fit your agenda).
-
No trolling.
Resources:
- selfh.st Newsletter and index of selfhosted software and apps
- awesome-selfhosted software
- awesome-sysadmin resources
- Self-Hosted Podcast from Jupiter Broadcasting
Any issues on the community? Report it using the report flag.
Questions? DM the mods!
founded 1 year ago
MODERATORS
1
2
3
4
Hi everyone!
**Postiz is an open-source social media scheduling tool that offers scheduling on: ** Instagram, YouTube, Dribbble, LinkedIn, Reddit, TikTok, Facebook, Pinterest, Threads, X, Slack, Discord, Mastodon and BlueSky.
Check it out here :) https://github.com/gitroomhq/postiz-app/
I have been working on mostly bug fixes lately and improving the platforms, some of the latest things:
-
Many failures of posting on small things like character limit or uploading size.
-
Fix problems in LinkedIn not loading pages.
-
Team invite was fixed :)
-
A bunch of docker changes to make it super easy to load. It's now live on: Coolify, Ptah soon Cloudron
**But the most important thing in the roadmap here is what I was mainly asked: **
-
Add and an option to schedule stories on Instagram and add music to them
-
Public API
-
YouTube community posts schedule
-
Google Business schedule
-
Auto Plugs (I'm super excited about this one): Once tweets get X likes, they will auto-repost, add comments to tweets, and so on; this will be sent to all social media.
-
SSO
-
I am happy to hear about more requests.
One clarification after seeing many comments over and self-hosted: Postiz will always be apache-2, no weird dual license thingy, and no enterprise-only SSO.
Postiz is not making much money. Today we are on a product hunt. If you can help me out, it would be amazing, but if not, I love you anyway :)
Thank you so much for this community for helping me with every post!

5
6
7
8
Hey all!
About three weeks ago, I introduced ChartDB to this community and received a great response with tons of positive feedback and feature requests. Thank you for the amazing support!
recap of ChartDB: For those new to ChartDB, it simplifies database design and visualization, similar to tools like DBeaver, dbdiagram, and DrawSQL, but is completely open-source and self-hosted.
https://github.com/chartdb/chartdb
Key features:
- Instant Schema Import - Import your database schema with just one query.
- AI-Powered DDL Export - Generate scripts for easy database migration.
- Broad Database Support - Works with PostgreSQL, MySQL, SQLite, MSSQL, ClickHouse, and more.
- Customizable ER Diagrams - Visualize your database structure as needed.
- Open-Source & Self-Hostable - Free, flexible, and transparent.
What’s New in v1.20 (2024-11-17)
- Sharing Capabilities - Import and export diagrams easily for better collaboration.
- Duplicate table: duplicate table from the canvas and sidebar.
- Snap to Grid - Toggle or hold shift to precisely position elements.
- New Templates Added - Now includes templates for Laravel, Django, Twitter, and more.
- Docker Build Support - Includes OpenAI key support for Docker builds.
Bug Fixes & Improvements:
- Optimized Bundle Size - Leaner builds for faster loading times.
- Internationalization (i18n) - Added support for Korean, Simplified Chinese, Russian, French, and more.
- Improved UX - Better interactions for editing diagram titles and smoother SQL export.
What’s Next?
- More sharing and collaboration enhancements.
- Expanded templates and language support.
- New deployment options and compatibility for more databases.
We’re building ChartDB hand-in-hand with this community and contributors. Your feedback drives our progress, and we’d love to hear more! Thank you to everybody who contributed!

9
10
11
publication croisée depuis : https://lemmy.pierre-couy.fr/post/805239
Happy birthday to Let's Encrypt !
Huge thanks to everyone involved in making HTTPS available to everyone for free !
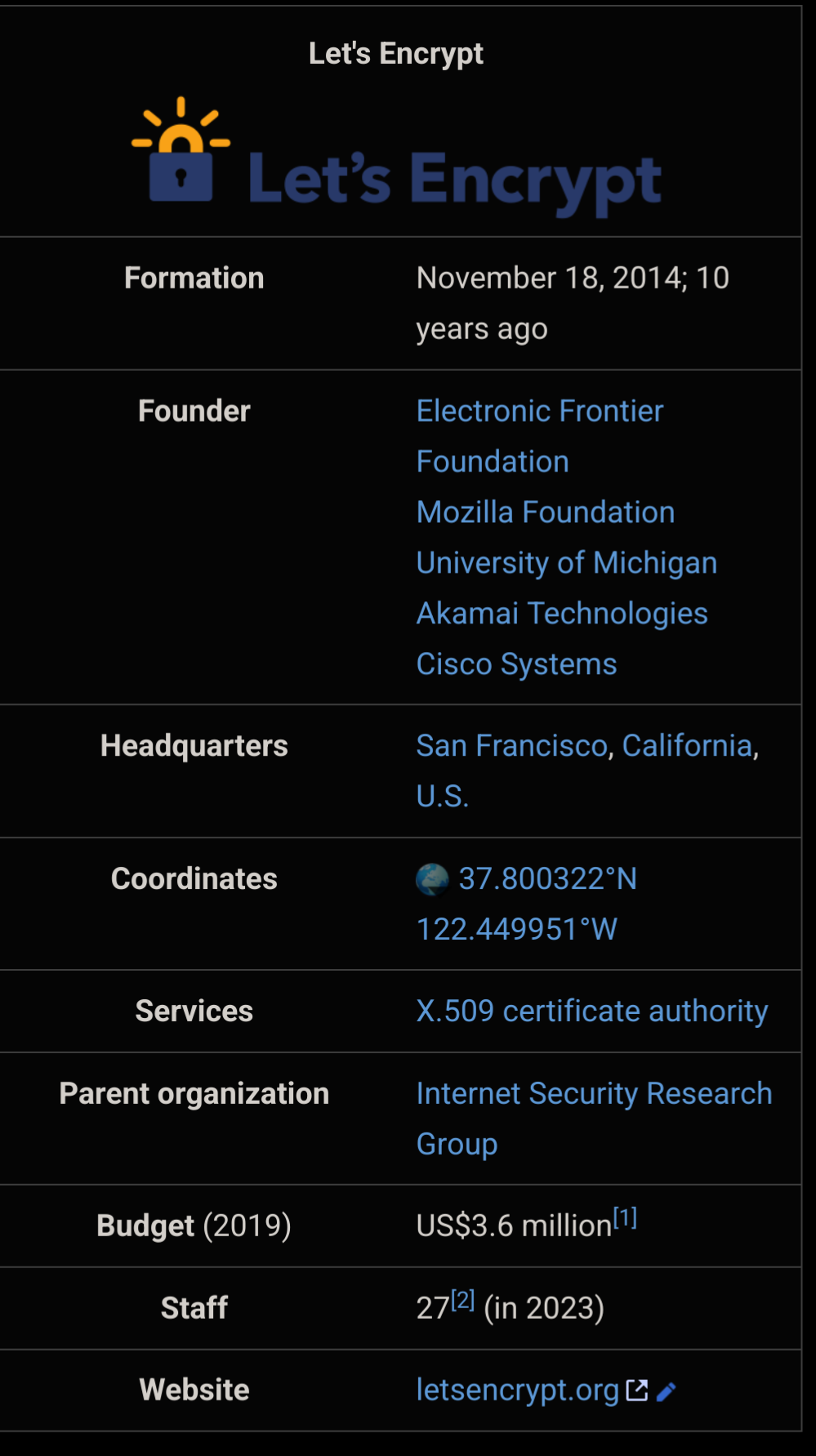
12
13
14

Only use jellyfin. Have a list of things want to update... but it works for now.
Yes that is a laptop usb cooler used as supplemental placebo cooling. Also a pc fan I have propped up against the hard drive feeding into the pi.
Can't recall last time used the ps4 or switch. But they're there

15
16
17
19
20
21
22
23
24
25
view more: next ›