{kind=link}
Very interesting that only 71% of humans got it right.
this post was submitted on 23 Feb 2026
712 points (97.3% liked)
Technology
85297 readers
3973 users here now
This is a most excellent place for technology news and articles.
Our Rules
- Follow the lemmy.world rules.
- Only tech related news or articles.
- Be excellent to each other!
- Mod approved content bots can post up to 10 articles per day.
- Threads asking for personal tech support may be deleted.
- Politics threads may be removed.
- No memes allowed as posts, OK to post as comments.
- Only approved bots from the list below, this includes using AI responses and summaries. To ask if your bot can be added please contact a mod.
- Check for duplicates before posting, duplicates may be removed
- Accounts 7 days and younger will have their posts automatically removed.
Approved Bots
founded 3 years ago
MODERATORS
I mean, I've been saying this since LLMs were released.
We finally built a computer that is as unreliable and irrational as humans... which shouldn't be considered a good thing.
I'm under no illusion that LLMs are "thinking" in the same way that humans do, but god damn if they aren't almost exactly as erratic and irrational as the hairless apes whose thoughts they're trained on.
Yeah, the article cites that as a control, but it's not at all surprising since "humanity by survey consensus" is accurate to how LLM weighting trained on random human outputs works.
It's impressive up to a point, but you wouldn't exactly want your answers to complex math operations or other specialized areas to track layperson human survey responses.
load more comments
(2 replies)
That "30% of population = dipshits" statistic keeps rearing its ugly head.
As someone who takes public transportation to work, SOME people SHOULD be forced to walk through the car wash.
I'm not afraid to say that it took me a sec. My brain went "short distance. Walk or drive?" and skipped over the car wash bit at first. Then I laughed because I quickly realized the idiocy. :shrug:
load more comments
(1 replies)
load more comments
(49 replies)
What worries me is the consistency test, where they ask the same thing ten times and get opposite answers.
One of the really important properties of computers is that they are massively repeatable, which makes debugging possible by re-running the code. But as soon as you include an AI API in the code, you cease being able to reason about the outcome. And there will be the temptation to say "must have been the AI" instead of doing the legwork to track down the actual bug.
I think we're heading for a period of serious software instability.
AI chatbots come with randomization enabled by default. Even if you completely disable it (as another reply mentions, "temperature" can be controlled), you can change a single letter and get a totally different and wrong result too. It's an unfixable "feature" of the chatbot system
load more comments
(10 replies)
I just tried it on Braves AI 
The obvious choice, said the motherfucker 😆
This is why computers are expensive.
Dirtying the car on the way there?
The car you're planning on cleaning at the car wash?
Like, an AI not understanding the difference between walking and driving almost makes sense. This, though, seems like such a weird logical break that I feel like it shouldn't be possible.
You're assuming AI "think" "logically".
Well, maybe you aren't, but the AI companies sure hope we do
load more comments
(4 replies)
The most common pushback on the car wash test: "Humans would fail this too."
Fair point. We didn't have data either way. So we partnered with Rapidata to find out. They ran the exact same question with the same forced choice between "drive" and "walk," no additional context, past 10,000 real people through their human feedback platform.
71.5% said drive.
So people do better than most AI models. Yay. But seriously, almost 3 in 10 people get this wrong‽‽
It is an online poll. You also have to consider that some people don't care/want to be funny, and so either choose randomly, or choose the most nonsensical answer.
load more comments
(1 replies)
Have you seen the results of elections?
load more comments
(18 replies)
and what is going to happen is that some engineer will band aid the issue and all the ai crazy people will shout “see! it’s learnding!” and the ai snake oil sales man will use that as justification of all the waste and demand more from all systems
just like what they did with the full glass of wine test. and no ai fundamentally did not improve. the issue is fundamental with its design, not an issue of the data set
load more comments
(2 replies)
I tried this with a local model on my phone (qwen 2.5 was the only thing that would run, and it gave me this confusing output (not really a definite answer...):
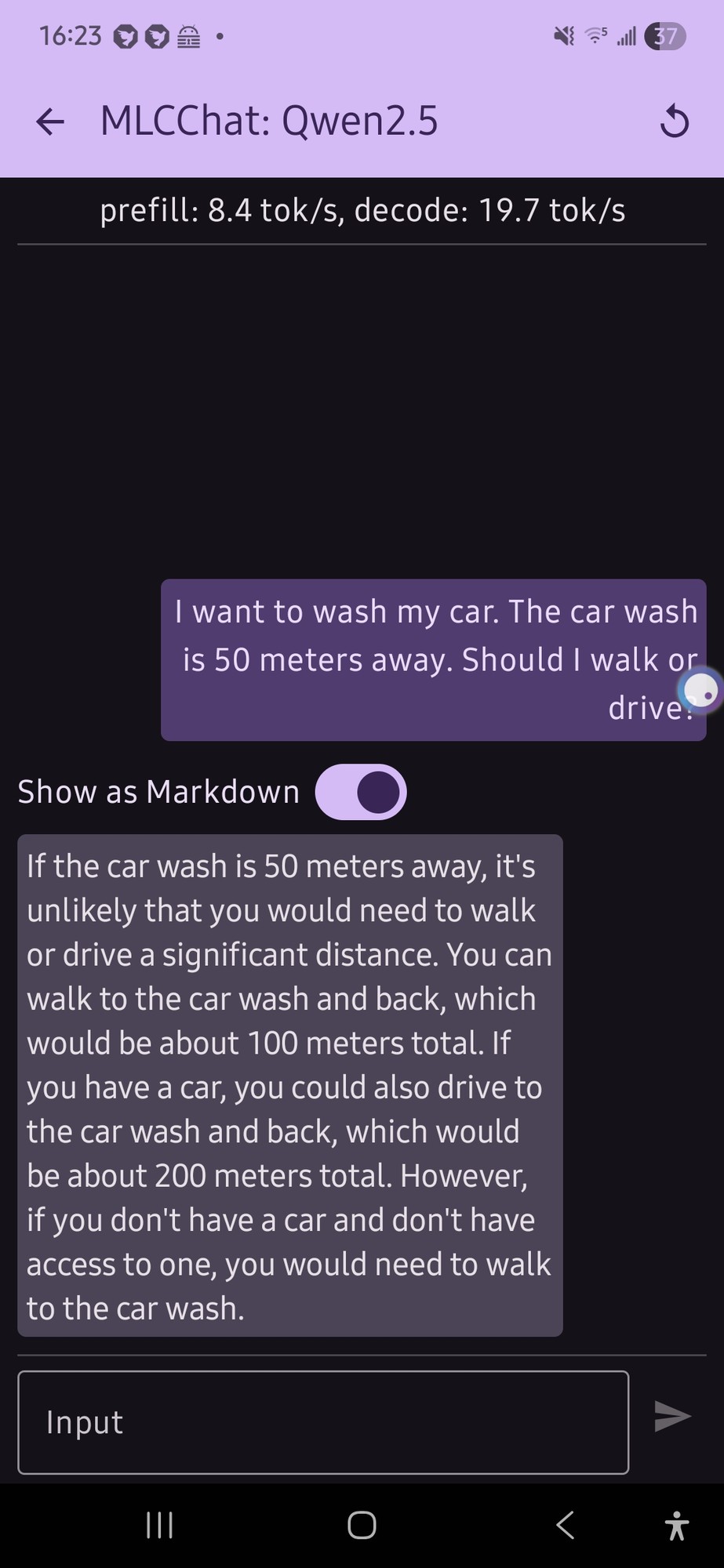
it just flip flopped a lot.
E: also, looking at the response now, the numbers for the car part doesn't make any sense
Honestly that's a lot more coherent than what I would expect from an LLM running on phone hardware.
load more comments
(2 replies)
I like that it's twice as far to drive for some reason. Maybe it's getting added to the distance you already walked?
load more comments
(2 replies)
load more comments
(2 replies)
I think it's worse when they get it right only some of the time. It's not a matter of opinion, it should not change its "mind".
The fucking things are useless for that reason, they're all just guessing, literally.
load more comments
(50 replies)

Gemini set to fast now provides this type of answer.
Extension cord? It must mean a hose extension.
Went to test to google AI first and it says "You cant wash your car at a carwash if it is parked at home, dummy"
Chatgpt and Deepseek says it is dumb to drive cause it is fuel inefficient.
I am honestly surprised that google AI got it right.
They probably added a system guardrail as soon as they heard about this test. it's been going around for a while now :)
load more comments
(4 replies)
load more comments
(2 replies)
I just asked Goggle Gemini 3 "The car is 50 miles away. Should I walk or drive?"
In its breakdown comparison between walking and driving, under walking the last reason to not walk was labeled "Recovery: 3 days of ice baths and regret."
And under reasons to walk, "You are a character in a post-apocalyptic novel."
Me thinks I detect notes of sarcasm......
load more comments
(3 replies)
I asked my locally hosted Qwen3 14B, it thought for 5 minutes and then gave the correct answer for the correct reason (it did also mention efficiency).
Hilariously one of the suggested follow ups in Open Web UI was "What if I don't have a car - can I still wash it?"
load more comments
(2 replies)
I want to wash my train. The train wash is 50 meters away. Should I walk or drive?
Fly, you fool
load more comments
(1 replies)
In school we were taught to look for hidden meaning in word problems - checkov's gun basically. Why is that sentence there? Because the questions would try to trick you. So humans have to be instructed, again and again, through demonstration and practice, to evaluate all sentences and learn what to filter out and what to keep. To not only form a response, but expect tricks.
If you pre-prompt an AI to expect such trickery and consider all sentences before removing unnecessary information, does it have any influence?
Normally I'd ask "why are we comparing AI to the human mind when they're not the same thing at all," but I feel like we're presupposing they are similar already with this test so I am curious to the answer on this one.
load more comments
(2 replies)
view more: next ›