My main question is about /run/user/1000:
- Should I avoid touching it?
- Could I delete it?
- Is there something wrong with it?
Background: I'm fairly new to Linux and just getting used to it.
I use fsearch to quickly find files (because my filenaming convention helps me to get nearly everything in mere seconds). Yesterday I decided to let it index from root and lower instead of just my home folder.
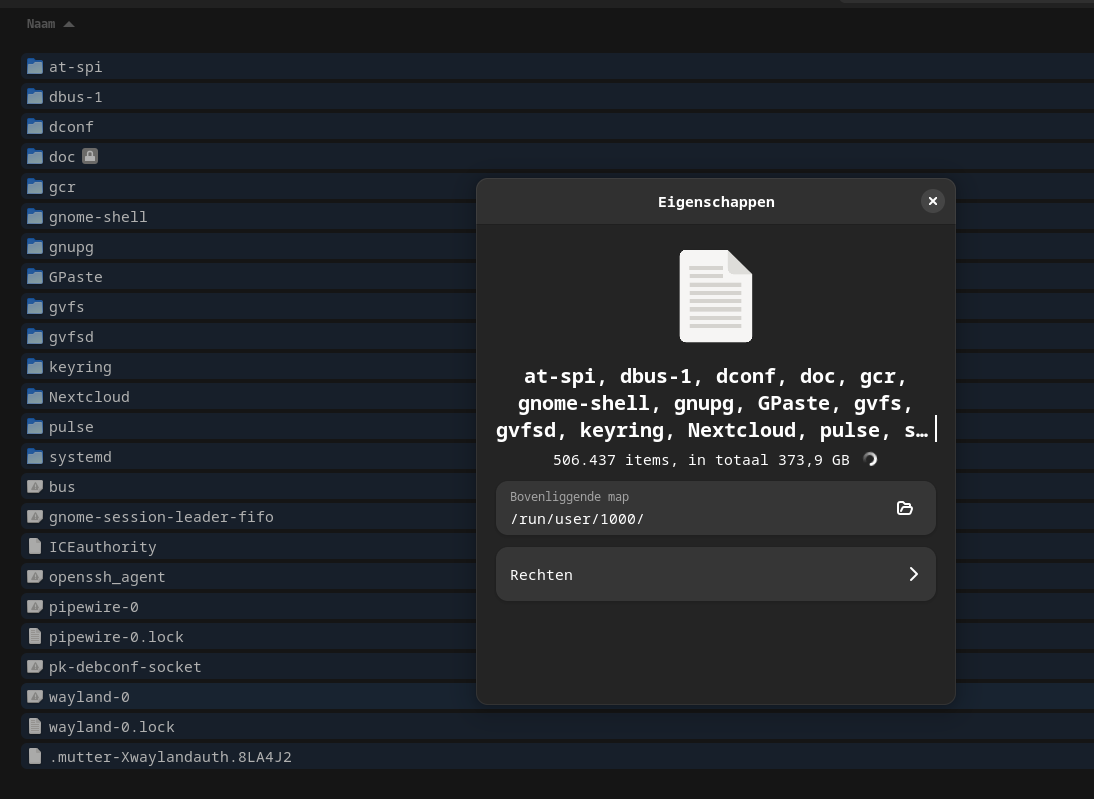
Then I got a lot of duplicate files. For example in subfolders relating to my mp3 player I even discovered my whole NextCloud 'drive' is there again: /run/user/1000/doc/by-app/org.strawberrymusicplayer.strawberry/51b78f5c/N
Searching: Looking for answers I read these, but couldnt make sense of it.
- https://unix.stackexchange.com/questions/162900/what-is-this-folder-run-user-1000
- https://forums.linuxmint.com/viewtopic.php?t=412850 So if its a bug with flatpaks I'm inclined to delete a certain db at ~/.local/share/flatpak/db
Puzzled:
- Is this folder some RAM drive so my disk doesnt show anything strange? Because this folder doesnt even show up at the root level.
- Are these even real? Because the size of it (aprox 370 GB) is even bigger then my disksize (screenshot).
Any tips about course of (in)action appreciated.
Another scenario would be all universities cooperate in one instance, like Surf does for all Dutch universities and colleges for vocational training.
https://social.edu.nl/home