Huh? What do you mean "if"? Such a PDF vulnerability literally did happen a few months ago; fixed in Firefox v.126: https://codeanlabs.com/blog/research/cve-2024-4367-arbitrary-js-execution-in-pdf-js/.
Huh? What do you mean "if"? Such a PDF vulnerability literally did happen a few months ago; fixed in Firefox v.126: https://codeanlabs.com/blog/research/cve-2024-4367-arbitrary-js-execution-in-pdf-js/.
There’s no real need for pirate ai when better free alternatives exist.
There's plenty of open-source models, but they very much aren't better, I'm afraid to say. Even if you have a powerful workstation GPU and can afford to run the serious 70B opensource models at low quantization, you'll still get results significantly worse than the cutting-edge cloud models. Both because the most advanced models are proprietary, and because they are big and would require hundreds of gigabytes of VRAM to run, which you can trivially rent from a cloud service but can't easily get in your own PC.
The same goes for image generation - compare results from proprietary services like midjourney to the ones you can get with local models like SD3.5. I've seen some clever hacks in image generation workflows - for example, using image segmentation to detect a generated image's face and hands and then a secondary model to do a second pass over these regions to make sure they are fine. But AFAIK, these are hacks that modern proprietary models don't need, because they have gotten over those problems and just do faces and hands correctly the first time.
This isn't to say that running transformers locally is always a bad idea; you can get great results this way - but people saying it's better than the nonfree ones is mostly cope.
Incredibly weird that this thread was up for two days without anyone posting a link to the actual answer to OP's question, which is g4f.
Difficulty is hardly the point of the post.
The thing I said I did? Yes; here's the processed image:
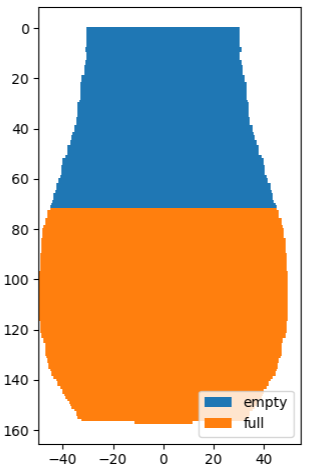
If you mean the math in the post, I can't read it in this picture but it's probably just some boring body-of-rotation-related integrals, so basically the same thing as I did but breaking apart the vase's visible shape into analytically simple parts, whereas I got the shape from the image directly.
This roughly checks out. I'm getting 66%, based on the methodology of cutting out the jug's shape from the picture and numerically integrating the filled and empty volume (e.g. if a row is d pixels wide, it contributes d^2 to the volume, either filled or empty depending on whether it's above or below the water level).

Note that openai's original whisper models are pretty slow; in my experience the distil-whisper project (via a tool like whisperx) is more than 10x faster.
Really? This is the opposite of my experience with (distil-)whisper - I use it to generate subtitles for stuff like podcasts and was stunned at first by how high-quality the results are. I typically use distil-whisper/distil-large-v3, locally. Was it among the models you tried?
How's musk related to this one?
My point is just that nobody really thinks it should be a free for all.
Don't made judgements about everybody based on one guy. I'm on an instance that doesn't defederate lemmygrad or lemmy.ml, so I commonly see utterly insane tankie takes in popular, and of course also in various comments - and yet I don't want those people to not have a platform. Because I trust just about noone to decide whether my opinions should be censored, and if that means also not censoring the opinions of people who I think are very wrong, I'm willing to take that trade.
I see. No, I don't think I have any specific questions at this point.
Sure, in Firefox itself it wasn't a severe vulnerability. It's way worse on standalone PDF readers, though: